As far as the theory goes, each output of the function amazing_hash has a fixed size, and is mapped to another output of the hash function, and another, and so on.
So, leaving aside the very first input, you have a function from a finite set to itself. The function may or may not be bijective, but it's not a required property of a hash function that it is. The domain of the function necessarily is divided up into:
- one or more cycles, plus
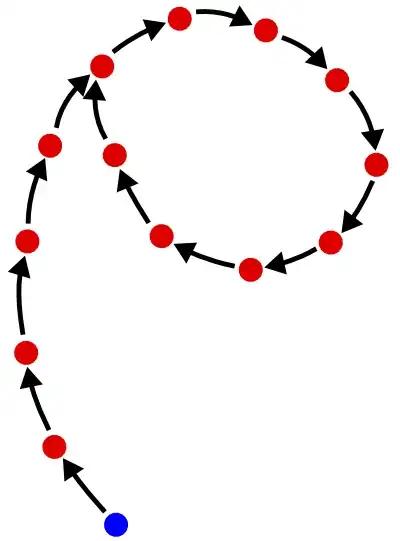
- zero or more "tails", that is to say sequences that lead into one of the cycles or into another tail. When two tails join consider it arbitrary which one is leading into the other one, but I'm going to use the number of tails later, so it has to be defined that way :-) Define also the "end" of a tail to be the point where it joins another tail or a cycle.
Every point, when iterated, is either part of a cycle to begin with or else it follows a tail, and the tails that tail joins, until it joins a cycle. That's a necessary property of a function from a finite set to itself. A path cannot run forever without entering a cycle, because there are only finitely many values and so eventually it must repeat one. You can therefore imagine the function visually as a lot of circles, with branches sticking out of the sides of them. The branches all lead into the circles.
With one iteration (that is, one further hash after the initial hash), how many collisions are there? Well, it's related to the number of tails, since the end of a tail is a place where two non-equal values have the same hash. Each join point implies there is a number of colliding values equal to the number of structures joining at that point. Every tail ends in a join, so if we define "tails" and "collisions" carefully then the number of collisions is just the number of tails.
After two iterations, how many collisions are there? It's the number of tails (since once two values are collided they stay collided), plus the number of new collisions caused by the extra iteration. The extra iteration causes a collision if "both sides" of a join point are at least 2 nodes long. So where two tails join they must both be at least 2 nodes long, and where a tail joins a cycle it must be at least a 2-cycle.
After n iterations, further collisions are generated by tails at least n nodes long, and n-cycles.
In the extreme case, a hash function that is bijective has no tails. This is theorem one of finite functions: every permutation partitions its domain into cycles. Then it should be easy to see that no matter how many iterations you do, there are no collisions (other than those caused by the initial hash, of course). Each point just moves around its cycle. By moving every point an equal number of steps around a cycle, they're still all in different positions.
Otherwise, to begin with the more iterations you do, the more collisions get generated as the tails merge into the cycles. However, there is an upper limit to this process, because every tail and every cycle has a finite length. Eventually you will cause no more collisions when you do more iterations. That won't happen until you've reached the length of the longest tail in your function.
This is all in theory: in practice the longest tail might still be rather larger than you have time to iterate. If so you would keep increasing the number of collisions for as long as you can practically run.
However, the number of collisions that each iteration introduces is still very small compared to the hash space, so small that it's incredibly unlikely you'll encounter a collision this way. How do we know this? Because if it wasn't, then Floyd's cycle-finding algorithm would be an effective means to find collisions in the hash function. The hash function would not be "amazing" per the assumptions of the question, it would be known to be broken :-)