Space reduction does occur, but not like that.
Secure hash functions are supposed to behave like what a random function would do on average (i.e., a function chosen uniformly among the set of possible functions with the same input and output lengths). MD5 and SHA-1 are known not to be ultimately secure (because we can find collisions for them more efficiently than we could with a random function), but they are still close enough approximations here (still, you should not use them except for interoperability with legacy implementations; you really should use a more modern and secure function like SHA-256).
So, assuming an n-bit output, if you hash all 2n strings of n bits, you can expect all the outputs to cover about 63.21% of the space of 2n possible output values (that’s 1-(1/e)). You lose a bit more than a third of the space. However, if you rehash all these obtained values again, you will loose much less than a third of them. The reduction factor is not constant for each round. After a few rounds, extra reduction per round is very small.
When you hash a given value many times successively, you are actually walking a “rho structure”, as in the figure below:
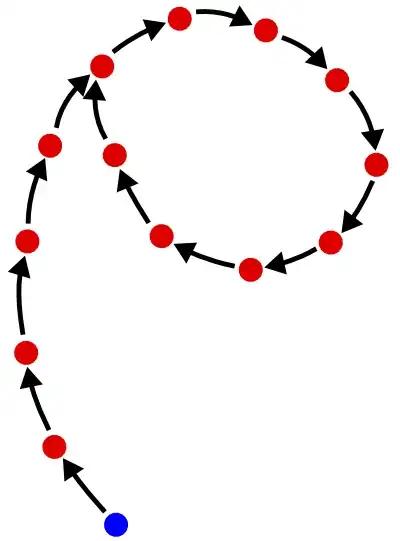
This structure is so named because it looks roughly like the Greek letter ρ, “rho”. Each dot is an n-bit value, and each arrow represents the application of your hash function. The blue dot is your starting point. So the idea is that by applying the function sufficiently many times, you end up in a cycle. Once on the cycle, successive applications of the hash function no longer reduce the space of possible values: you just walk around the cycle, indefinitely. The cycle length is then the minimal space size that you can ever achieve.
The lengths of both the “tail” (the values you get through before entering the cycle) and the “cycle” itself are, on average, 2n/2. So, for a hash function with a 128-bit output, successive applications will not reduce the space below 264, a quite large value; an even reaching that minimal space will take, on average, 264 hash function evaluations, which is expensive.
Finding the cycle by walking the rho structure is actually the basis for Floyd’s cycle-finding algorithm, which is one of the generic algorithms which can be used to build collisions for a hash function: in the rho structure, at the point where the tail is attached to the cycle, there is a collision (two distinct values which hash to the same value). For a cryptographically secure hash function, finding collisions is supposed to be hard; in particular, Floyd’s algorithm should be computationally infeasible, which is achieved by making n big enough (e.g., n = 256 for SHA-256: this raises the cost of Floyd’s algorithm to 2128, i.e., not realistically feasible on Earth).
In other words: if you select a secure hash function, with a wide enough output (a prerequisite for being secure), then you will not be able to reach the cycle and/or walk it, and your security will not suffer from any “space reduction”. Corollary: if you have a problem of space reduction, then you are not using a secure hash function, and that is the problem you need to fix. So, use SHA-256.