A good answer has already been given by sasha, but I want to look at this from another angle; specifically, what memcpy actually does (in terms of what code gets executed).
Allowing for the possibility of minor bugs in this quick-and-dirty implementation, a trivial implementation of memcpy() that meets the C89/C99/POSIX function signature and contract might be something not entirely unlike:
/* copy n bytes starting at source+0, to target+0 through target+(n-1), all inclusive */
void memcpy (void* target, void* source, size_t n)
{
for (size_t i = 0; i < n; i++)
{
*target++ = *source++;
/* or possibly the here equivalent: target[i] = source[i]; */
}
}
Now, a real implementation would probably do the copying in larger chunks than one byte at a time to take advantage of the wide memory (RAM) interconnect buses of today, but the principle remains exactly the same.
For the purposes of your question, the important part to note is that there is no bounds checking. This is by design! There are three important reasons for why this is so:
- C is often used as a operating system programming language, and it was designed as a "portable assembler". Thus, the general approach to many of the old library functions (of which memcpy() is one), and the language in general, is that if you can do it in assembler, it should also be doable in C. There are very few things you can do in assembler but not in C.
- There is no way to, given a pointer to a memory location, know how much memory is properly allocated at that location, or even if the memory pointed to by the pointer is allocated at all! (A common trick to speed up software in the old days of early x86 systems and DOS was to write directly to the graphics memory to put text on the screen. The graphics memory, obviously, was never allocated by the program itself; it was just known to be accessible at a specific memory address.) The only way to really find out if it works is to read or write the memory and see what happens (and even then I believe accessing uninitialized memory invokes undefined behavior, so basically, the C language standard allows anything to happen).
- Basically, arrays degenerate to pointers, where the unindexed array variable is the same thing as a pointer to the start of the array. This is not strictly true in every case, but it's good enough for us right now.
It follows from (1) that you should be able to copy any memory you want to, from anywhere to anywhere. Memory protection is Someone Else's Problem. Specifically, these days it's the responsibility of the OS and MMU (these days generally part of the CPU); the relevant portions of the OS themselves likely being written in C...
It follows from (2) that memcpy() and friends need to be told exactly how much data to copy, and they have to trust that the buffer at the target (or whatever else is at the address pointed to by the target pointer) is sufficiently large to hold that data. Memory allocation is The Programmer's Problem.
It follows from (3) that we can't tell how much data is safe to copy. Making sure memory allocations (both source and destination) are sufficient is The Programmer's Problem.
When an attacker can control the number of bytes to copy using memcpy(), (2) and (3) break down. If the target buffer is too small, whatever follows it will be overwritten. If you are lucky, that will result in a memory access violation, but C the language or its standard libraries doesn't guarantee that it will happen. (You asked it to copy memory contents, and it either does that, or it dies trying, but it doesn't know what was intended to be copied.) If you pass a source array that is smaller than the number of bytes you ask for memcpy() to copy, there is no reliable way for memcpy() to detect that such is the case, and it will happily barrage on past the end of the source array as long as reading from the source location and writing to the target location works.
By allowing an attacker to control n in your example code, in such a way that n is larger than the maximum size of the array on the source side of the copy, memcpy() will because of the above points happily keep copying beyond the length of the intended source array. This is basically the Heartbleed attack in a nutshell.
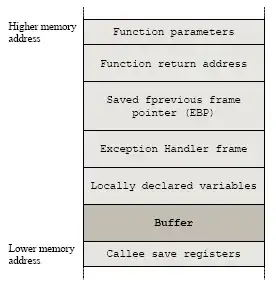
That is why the code leaks data. Exactly what data is leaked depends both on the value of n and how the compiler lays out the machine language code and data in memory. The diagram in sasha's answer gives a good overview, and every architecture is similar but different.
Depending on how exactly your variable buf is declared, allocated and laid out in memory, you might also have what is known as a stack smashing attack where data needed for the proper operation of the program is overwritten, and the data that overwrote whatever was there is subsequently referred to. In mundane cases this leads to crashes or nigh-impossible-to-debug bugs; in severe, targetted cases, it can lead to arbitrary code execution fully under the control of the attacker.