I'm going to barge in and talk about entropy and probability for a little bit and hopefully this will help you understand.
Firstly what is probability? This is actually an open question amongst statisticians but here's the frequentialist definition: we say that if a fair coin is flipped, it has probability 0.5 of coming up heads. However, if you flip a coin you might observe that the first five results are all heads, which does not look right. So, the frequentialist says that if you were to flip the coin "enough" times, you would eventually find that one in two of the coin tosses are heads.
The key is that probability says nothing about what will actually happen. A high-entropy password could be guessed on the very first try by simple luck, regardless of possible outcomes and so on.
Now what is entropy? If you started saying "well it's the number of possible outcomes..." you might be right in a generating-some-random-data context, but this is the perfect example of where you really need to understand what is going on underneath.
Firstly, let's talk about self-information. This is a random variable (which means there are a number of possible outcomes) that varies over the probability of each outcome (and then we take -log2(P(X)) to encode it into "bits" of information). So we need to assign each outcome a probability.
As others have pointed out, some variations of PIN choice are more likely. All the same numbers (1111, 2222, 3333, ...), Birthdays (20XX, 19XX) and so on. You should assign higher probability to these numbers because simply put people are more likely to pick them and are certainly not going to pick a random sequence. How you assign probability to other numbers is entirely up to you and really depends on how much you know about the process of choosing a pin.
Now, entropy, or to keep @codesinchaos happy, Shannon entropy specifically, is the mean of the self information distribution. It's the "most likely" value of self-information given the probabilities of each choice. What does this mean? As the current top-voted answer says, it is a measure of the choice process and how good it is, not the pin itself.
What happens when you take out high probability choices like 1111, 2222, 3333? These outcomes give very low self information (-log(P(X)) is small for large probabilities, since we expect them to occur) and so removing them moves the distribution to the right, i.e., moves the location of the distribution towards the centre. This will increase its mean. So, removing choices most people would otherwise make with high probability actually increases entropy.
Let's look at entropy in a different way: if you were going to guess PINs, in what order would you try them (assuming no lockout)? You would begin with the most likely PINs for certain. What entropy is saying is that if you repeated this experiment enough times (i.e. tried to guess the PIN of a large number of cards whose PINs were chosen with the exact same logic) then a lower entropy choice would give you, the attacker, success more quickly.
Again, this remains a question of what might happen in the theoretical case of many cards, not what might happen because the attacker gets lucky.
Here is your executive summary:
- What entropy becomes is depends on how you assign probabilities to the outcome space.
- Without a doubt, if you leave humans to choose PINs, they will choose certain values with much higher probability than others.
- This means you can't assume the underlying distribution is uniform and say "entropy==number of outcomes".
- If you take out the highest probability poor-choice options, entropy goes up.
- Entropy, like probability of guessing correctly, says absolutely nothing about whether an attacker will get lucky and guess your PIN correctly. It simply says that in theory better entropy gives your attacker a harder time.
Now, to round out my answer, let us look at practicalities. If we are going to compare to passwords, or hash function output choices, or random data, PINs suck. If you give an attacker and defender free choice of PIN guess and no other information, the number of guesses to be right 50% of the time (birthday paradox) is ridiculously low. PINs would make lousy hash functions.
However, humans cannot memorise 128-bits of data very well, especially when drunk and trying to pay for a kebab using chip-and-pin. PINs are therefore a pragmatic compromise and with three guesses as a limit, aside from an attacker getting very lucky, you should be safe.
TL;DR Removing the choice of more likely PINs from your possible choices improves your chances when faced with an attacker that will not be guessing at random (i.e. most attackers).
Edit: I think this dicussion warrants some mathematics now. Here is what I am going to assume in my calculations:
- We are using 4-digit PINs
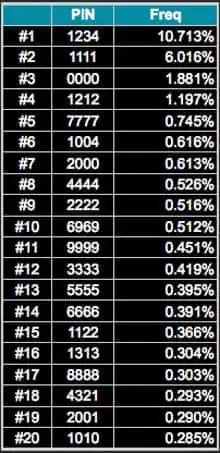
The data from Raesene's link is correct, i.e. that:
#1 1234 10.713%
#2 1111 6.016%
#3 0000 1.881%
#4 1212 1.197%
#5 7777 0.745%
#6 1004 0.616%
#7 2000 0.613%
#8 4444 0.526%
#9 2222 0.516%
#10 6969 0.512%
#11 9999 0.451%
#12 3333 0.419%
#13 5555 0.395%
#14 6666 0.391%
#15 1122 0.366%
#16 1313 0.304%
#17 8888 0.303%
#18 4321 0.293%
#19 2001 0.290%
#20 1010 0.285%
- I am also going to assume that any PIN not mentioned in this list has an equal chance of being chosen from the remaining, "unallocated" probability (1-total probability consumed above). This is almost definitely incorrect, but we only have so much data.
To compute this, I used the following sage code:
def shannon_entropy(probabilities):
contributions = [p * (-1*log(p,2)) for p in probabilities]
return sum(contributions)
Computes the actual shannon entropy for a given set of probabilities.
import itertools
total_outcomes = 10.0^4
probability_random_outcome = 1 / total_outcomes
probability_random_outcome
maximum_entropy = -log(probability_random_outcome, 2)
maximum_entropy
maximum_entropy_probability_list = list(itertools.repeat(probability_random_outcome, total_outcomes))
maximum_entropy_calculated = shannon_entropy(maximum_entropy_probability_list)
print(maximum_entropy)
print(maximum_entropy_calculated)
Demonstrates my function accurately computes maximum entropy, by taking a list of 10^4 probabilities, each at 1/10^4.
Then
probability_list_one = [10.713/100, 6.016/100, 1.881/100, 1.197/100, 0.745/100, 0.616/100, 0.613/100, 0.526/100,0.516/100, 0.512/100, 0.451/100, 0.419/100, 0.395/100, 0.391/100, 0.366/100, 0.304/100, 0.303/100,0.293/100,0.290/100,0.285/100]
outcome_count_one = 10^4 - len(probability_list_one)
print("Outcome count 1:", outcome_count_one)
probability_consumed_one = sum(probability_list_one)
print("Probability consumed by list: ", probability_consumed_one)
probability_ro_one = (1-probability_consumed_one)/outcome_count_one
entropy_probability_list_one = probability_list_one + list(itertools.repeat(probability_ro_one, outcome_count_one))
entropy_one = shannon_entropy(entropy_probability_list_one)
entropy_one
Here, as I said above, I take those 20 probabilities and assume the rest of the probabilities are distributed evenly between the remaining outcomes, by extending the list with each probability set evenly. The computation is performed.
probability_list_two = [6.016/100, 1.881/100, 1.197/100, 0.745/100, 0.616/100, 0.613/100, 0.526/100,0.516/100, 0.512/100, 0.451/100, 0.419/100, 0.395/100, 0.391/100, 0.366/100, 0.304/100, 0.303/100,0.293/100,0.290/100,0.285/100]
outcome_count_two = 10^4 - len(probability_list_two)-1
print("Outcome count 2:", outcome_count_two)
probability_consumed_two = sum(probability_list_two)
print("Probability consumed by list: ", probability_consumed_two)
probability_ro_two = (1-probability_consumed_two)/outcome_count_two
entropy_probability_list_two = probability_list_two + (list(itertools.repeat(probability_ro_two, outcome_count_two)))
entropy_two = shannon_entropy(entropy_probability_list_two)
entropy_two
In this instance, I remove the most likely PIN, 1111 and recompute entropy.
From these results, you can see that randomly chosing a PIN has 13.2877 bits of entropy. Repeating this experiment with one PIN removed gives us 13.2876 bits
Choosing a PIN given those probabilities of choice for those 20 PINs and otherwise choosing randomly means your choice as 11.40 bits of entropy, out of a possible 13.2877 bits. From this base, blocking PIN 1111 and otherwise allowing the remaining 19 obvious PINs and all other PINs chosen with equal probability has entropy 12.33 bits, out of a possible 13.2876 bits.
I hope this explains why many of the answers are saying entropy is going down, rather than up. They're considering maximum possible entropy, rather than the average entropy (shannon entropy) of the system taking into account the possibility of choice. A better measure is the shannon entropy, since it takes into account the probability of each choice being made overall and so how an attacker will likely proceed in attacking.
As you can see, blocking that PIN 1111 significantly increases shannon entropy, at a slight cost to overall possible entropy. If you want to argue about entropy, basically, removing the PIN 1111 massively helps.
For reference that XKCD comic calculates entropy of poor passwords at about 28 bits and entropy of good ones higher, at 44 bits. Again it depends on what assumptions are being made as to the probabilities of certain choices but this should also show that PINs suck in terms of entropy and the N-tries limit for small N is the only sane way to proceed.
Public sage worksheet